The technical details behind how we built PatentPT
As research in the language modeling space advances, there need to be more accompanying practical guides on how to finetune and deploy large language models on a custom text corpus. Yet, in practice, finetuned LLMs (like BloombergGPT) and ensembles of these finetuned LLMs are precisely where the industry's future is heading - instead of a singular general LLM API to rule them all.
PatentPT Features
If you have ever used https://www.uspto.gov/patents, you may have been unimpressed with the rigidly structured search provided, likely running on Cobalt servers without any neural network execution. So, there was ample opportunity and demand from the legal industry for an LLM-enabled approach to leveraging and search/retrieval of the US patent corpus.
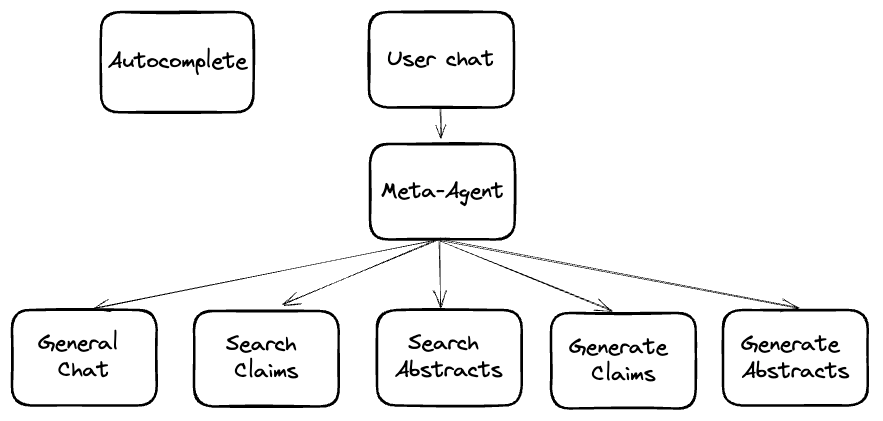
Specifically, we wanted our PatentPT to have the following features:
- Autocomplete
- Patent search on abstract
- Patent search on claims
- Abstract generation
- Claim generation
- General chat
To provide a simple, unified chat experience, we elected to have a meta agent sitting on top of these capabilities, routing the user to the PatentPTs capability.
PatentPT features
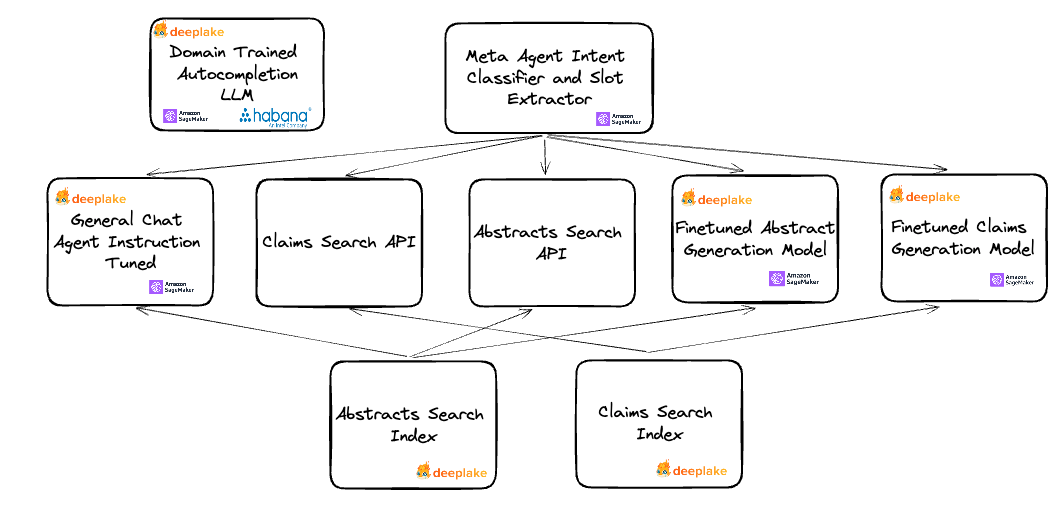
PatentPT Technical Architecture
To stand up these APIs, we needed to create an ensemble of finetuned LLM models and search indices to provide the richest PatentPT experience.
To accomplish this, we chose to first domain train a base LLM on the patent corpus of text, providing a base for our finetuning routines and our autocompletion API out of the box - this network also provides a custom featurizer for our search indices. Next, we finetuned LLMs for generation and chat off the base domain-trained LLM using PEFT techniques. Using our custom featurizer, we index patents on abstract and claim to create search indices to power our various APIs - hooking them up to the search APIs and providing context for generation and chat.
PatentPT Technical Architecture
PatentPT Dataset
The USPTO dataset consists of over 8 million patents, each broken down into fields - title, classification, publication_date, abstract, description, claims , etc.
dict_keys(['bibliographic_information', 'source_file', 'abstract', 'citations', 'assignees', 'classifications', 'inventors', 'brief_summary', 'foreign_priority', 'other_citations', 'detailed_description', 'claim_information'])
dict_keys(['bibliographic_information', 'source_file', 'abstract', 'citations', 'assignees', 'classifications', 'inventors', 'detailed_description', 'claim_information'])
dict_keys(['bibliographic_information', 'source_file', 'abstract', 'citations', 'assignees', 'classifications', 'inventors', 'detailed_description', 'claim_information'])The corpus of text in the USPTO dataset spans 40 billion words, filling a 350 GB text file, which, while short of the full size of the large pretraining LLM datasets, like the stack, it is enough to make a full finetuning pass on an LLM without losing the semantic richness as you would with a smaller domain training dataset.
As is typical with a project like this, we spent much time preparing our dataset for training from the USPTO XML files, using this open-source USPTO parser as a base.
Domain Training Patent GPT
To domain train our base patent GPT LLM, we used the entire patent corpus of 40 billion words. For hardware, we chose Habana® Labs' (an Intel® company) first-generation Intel Gaudi® AI deep learning processor, an instance with 8 HPUs. Habana HPUs are competitive with the latest and greatest GPUs, particularly for training transformer models. We trained our model with a CLM objective using the Optimum library from Huggingface, which has excellent Habana API bindings for running training on HPU. Optimum Intel interfaces the HuggingFace Transformers and Diffusers libraries and Habana HPUs. It provides tools that facilitate effortless model loading, training, and inference on single- and multi-HPU settings for tasks such as text classification, question answering, or language modeling!
For our dataloader, we used the Deep Lake performant dataloader to stream data loading into our model.
Tokenizing the dataset alone ran for 18 hours on our 8 HPU machine, while training ran for 24 days, at which point validation loss had fully converged.
We used our domain-trained LLM for the autocompletion API as is. And we used the domain-trained LLM as a base for our downstream finetuning.
Finetuning Generation Models
The next step in our training routines was to finetune generation models for abstracts and claims lists. To do so, we constructed datasets of description by abstract and claims and fed those datasets through a generation objective of our LLM.
Again, we loaded our dataset into Deep Lake for this process and took advantage of the Deep Lake dataloader. During this process, we did not tune all of our LLMs model weights; instead, we used the HuggingFace PEFT library to tune LORA weights for each objective.
Finetuning General Chat
We used PEFT techniques to fine-tune the chat to keep the general patent knowledge learned from our domain training routine.
Creating Custom Featurizers
We pulled a custom featurizer from our domain-trained open-source model to set up our search APIs. To do so, we pull out the representations from the last hidden layer. We found these features more robust in practice than general sentence embedders.
Standing up Search Indices
With our custom featurizer, we indexed the corpus of patents on the abstract and claim fields. We found that indexing the entire list of claims concatenated did not provide good signals to our chat interface in practice.
For a Vector DB, we chose the managed version of Deep Lake vector database, that provides features such as Deep Memory for increased retrieval accuracy, as well as an optimized HNSW index for up to 75% lower cost without impact on the speed - we chose this database due to its native Deep Lake LangChain integration, cloud deployment, fast query time, and TQL language that made filtered queries easy relative to competitors like Weaviate, Opensearch, Elasticsearch, and Pinecone.
To create our index, we extended the fields list in the Deep Lake object in Langchain but otherwise used that integration as is.
Our vectorization process ran for eight days on a single V100 GPU.
Deploying Search APIs
Once our search indices stood up, we wrote APIs around them to provide context to our chat queries and provide patent searches.
We used the Deep Lake TQL queries to filter our search queries, which allows you to filter your vector database for metadata efficiently. Here is a snippet of what one of those TQL queries looks like:
pip install deeplake==3.9.27search_deeplake_claims_time = time.time()
embedding = model.encode([query_text])[0]
embedding_search = ",".join([str(item) for item in embedding])
if "year" in filters.keys():
year_filter = f"filing_year = '{filters['year']}'"
else:
year_filter = ""
if "classification" in filters.keys():
classification_filter = "classification = '" + filters["classification"] + "'"
else:
classification_filter = ""
if year_filter != "" and classification_filter != "":
tql_query = f"select * from (select *, cosine_similarity(embedding, ARRAY[{embedding_search}]) as score WHERE {year_filter} and {classification_filter} ) order by score desc limit {top_k}"
elif year_filter != "" and classification_filter == "":
tql_query = f"select * from (select *, cosine_similarity(embedding, ARRAY[{embedding_search}]) as score WHERE {year_filter}) order by score desc limit {top_k}"
elif year_filter == "" and classification_filter != "":
tql_query = f"select * from (select *, cosine_similarity(embedding, ARRAY[{embedding_search}]) as score WHERE {classification_filter}) order by score desc limit {top_k}"
else:
tql_query = f"select * from (select *, cosine_similarity(embedding, ARRAY[{embedding_search}]) as score) order by score desc limit {top_k}"
ds_view = ds.query(tql_query)
patents = []
for i in range(len(ds_view)):
patents.append(json.loads(ds_view.patent[i].data()))search_deeplake_claims_time = time.time()
embedding = model.encode([query_text])[0]
embedding_search = ",".join([str(item) for item in embedding])
if "year" in filters.keys():
year_filter = f"filing_year = '{filters['year']}'"
else:
year_filter = ""
if "classification" in filters.keys():
classification_filter = "classification = '" + filters["classification"] + "'"
else:
classification_filter = ""
if year_filter != "" and classification_filter != "":
tql_query = f"select * from (select *, cosine_similarity(embedding, ARRAY[{embedding_search}]) as score WHERE {year_filter} and {classification_filter} ) order by score desc limit {top_k}"
elif year_filter != "" and classification_filter == "":
tql_query = f"select * from (select *, cosine_similarity(embedding, ARRAY[{embedding_search}]) as score WHERE {year_filter}) order by score desc limit {top_k}"
elif year_filter == "" and classification_filter != "":
tql_query = f"select * from (select *, cosine_similarity(embedding, ARRAY[{embedding_search}]) as score WHERE {classification_filter}) order by score desc limit {top_k}"
else:
tql_query = f"select * from (select *, cosine_similarity(embedding, ARRAY[{embedding_search}]) as score) order by score desc limit {top_k}"
ds_view = ds.query(tql_query)
patents = []
for i in range(len(ds_view)):
patents.append(json.loads(ds_view.patent[i].data()))On receiving patents for a search, we return that list in the search APIs or pass those patents on as context to our chat APIs.
Deploying LLM Inference APIs
Once our search APIs were deployed, the last thing remaining for the backend was to deploy our LLMs to the cloud for scalable inference. We deployed our finetuned models on top of the HuggingFace DLC to Amazon Sagemaker.
The Final Application
With our final ensemble of finetuned LLMs and search APIs constructed, we could put our meta agent LLM in front of our APIs to route user queries to their proper location. We wrote a simple flask server to run each inference and deployed it onto an AWS p3.2xlarge machine to make the vectorization calls locally with the rest of the app.

Generating claims for an electrical circuit invention

Searching for ironing board patents
Conclusion
While the stack for training and deploying finetuned LLMs in practice is far from solidified, we have summarized an efficient approach in this post, working with the latest and most remarkable technologies in the space right now, including:
- Deep Lake from Activeloop
- Hugging Face Optimum by Intel and training routines
- Habana Gaudi HPU hardware
PatentPT is one use case for finetuning LLMs, where you are likely to find much greater accuracy and control over your LLMs output than simply constructing prompts consumed by general AI APIs.
Disclaimers
Performance varies by use, configuration, and other factors. Learn more on the/Performance Index site. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details.
No product or component can be absolutely secure. Your costs and results may vary. For workloads and configurations, visit 4th Gen Xeon® Scalable processors at www.intel.com/processorclaims. Results may vary. Intel technologies may require enabled hardware, software or service activation. Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy. Intel® technologies may require enabled hardware, software, or service activation.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.